!!! In Arbeit !!!
Wir wollen auf diesen Seiten etwas die theoretische
Seite unseres Programms beschreiben, sowie dessen Umsetzung
in unserem Programm. Da zu geben wir vorerst eine kurze Einführung
in die verwendeten Algorithmen, bevor wir beschreiben, wie wir das Ganze in
der Programmiersprache C umgesetzt haben.
Theorie:
Bevor wir anfangen unseren Quellcode näher zu erklären, sollten einige
theoretische Fragen geklärt werden.
Nun was ist Kompression und warum wird es benötigt? Auch in der heutigen
Zeit der Breitbandinternetanschlüsse und Gigabytefestplatten sind Daten
noch immer gleichzusetzen mit Kosten, dh. je mehr Daten übertragen/gespeichert
werden müssen, umso mehr "kostet" die jeweilige Information.
Um diese Datenmengen möglichst gering zu halten, wurden im Laufe der Zeit
Verfahren (=Algorithmen) entwickelt, die in Daten überflüssige Information
aufspüren und diese dann kürzen. Dies kann man sich in etwa wie Fließbandarbeit
vorstellen. Ein festgesetzter Arbeitsprozeß wird hintereinander ausgeführt.
Dabei werden wiederholte, unnötige (redundante Information entdeckt) und
verändert. Bei diesem Prozess wird prinzipiell in 2 Arten unterschieden:
- die reversible Komprimierung: wichtig dabei ist, dass die
komprimierten Daten wieder genau in die Ursprungsform zurückgeführt
werden können (z.B. alle möglichen Archivprogramme wie WinZIP oder
dergleichen und auch unser kleines Programm "niCE")
- die irreversible Komprimierung: Im Gegensatz zur vorhergenannten
Methode werden hier irrelevante Daten komplett gestrichen und gehen somit
für immer verloren. Ein bekanntes Dateiformat, das diese Art der Komprimierung
nützt, ist das MP3 Format für Musikdateien. Dabei werden im Gegensatz
zu normalen Musikstücken von der CD Töne, die das menschliche Gehör
ohnehin nicht wahrnehmen kann, weggeschnitten. Somit tritt ein nicht hörbarer
Qualitätsverlust auf bei fallender Datenmenge.
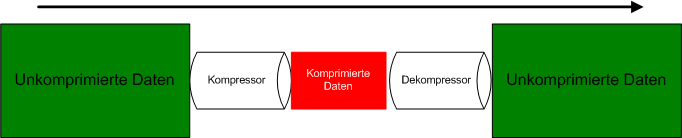
Ich werde mich fortan mit der reversiblen Datenkomprimierung beschäftigen.
|
Diagramm zur Funktionsweise der reversiblen Komprimierung: Daten am
Anfang und Daten am Ende sind ident.
|
Bei unserem Programm haben wir 2 gängige Algorithmen verwendet:
Lauflängenkomprimierung:
Wie bereits erwähn handelt es sich bei diesem Verfahren nicht gerade um
das effizienteste. Jedoch liegt sein Vorteil in der Geschwindigkeit. Die Idee
hinter dem Verfahren ist es, bei wiederholten Zeichen, statt tatsächlich
jedes Zeichen zu wiederholen, ein Escape Zeichen zu vereinbaren. Dieses weist
darauf hin, dass es beim nächsten Zeichen um kein normales Zeichen in der
Bitfolge handelt, sondern um mehrere. Nun weiss der Dekomprimierer, dass sich
das nächste Zeichen wiederholen wird, bleibt nur noch die Frage offen,
wie oft die Wiederholung stattfinden wird. Somit wird das 3.te eingelesene Zeichen
einfach als Zahl interpretiert.
Ein Beispiel, um die Sache vielleicht etwas klarer zu gestalten:
Gegeben sei der Text: blaaaaaabbbllllaa
Die erste Idee wäre nun die wiederholten Buchstaben zu streichen und dafür
eine Zahl zu notieren:
Dabei wäre folgendes Ergebnis zu erwarten: bla(6)b(3)l(4)a(2)
- Exkurs: Bytes (= 8 Bits = Zahlen von 0 - 255) können
für gewöhnlich als ASCII Zeichen oder als normale Zahlen ausgelesen
werden. Wird ein Byte als ASCII Zeichen ausgelesen, so wird die ausgelesene
Zahl als Zeichen interpretiert. Dazu gibt es eine Tabelle, in der alle Zahlen
einem Zeichen zugeordnet sind. Wie ein ausgelesenes Byte zu interpretieren
ist, ist die Entscheidung des Programmierers.
- In den Beispielen sollen normale Zeichen als ASCII Code angenommen werden,
Zahlen in Klammern jedoch als "normale" Zahlen.
Wie im Exkurs nun klar geworden sein sollte, ist aus der Bitfolge nicht ersichtlich,
ob es sich um eine als ASCII Zeichen zu interpretierende Zahl handelt oder als
normale Zahl. Hat man diese Überlegung verstanden sollte, man sich das
vorhergehende Beispiel noch einmal ansehen:
bla(6)b(3)l(4)a(2)
Woher weiss das Programm, wann die "5" nicht als Buchstabe,
sondern als Zeichen zu lesen ist?
Die Lösung erfordert wieder ein sogenanntes ESCAPE Symbol. Das soll ein
Symbol sein, das beim Einlesen nicht als normales Symbol behandelt wird, sondern
Ankündigt das nun eine spezielle Aktion folgt. Genau ein derartiges Symbol
wird man hier benötigen. Dabei gibt es mehrere Möglichkeiten. Die
von uns gewählte und auch näher beschriebene, war es die Datei vor
dem Komprimieren zu durchsuchen und das am wenigsten vorkommende Zeichen zu
ermitteln. Dieses haben wir dann als ESCAPE Zeichen benutzt.
In unserem Beispieltext kommt neben vielen anderen Zeichen kein "u"
vor. Somit könnten wir das "u" als ESCAPE Zeichen nutzen. Dabei
würde folgende Zeichenkette entstehen:
blua(6)ub(3)ul(4)ua(2)
Ein "u" in unserem Text würde somit aussagen: Achtung
gleich folgt ein Buchstabe der sich wiederholt.
Um zu gewährleisten, dass beim Dekomprimieren auch das ESCAPE Zeichen
eindeutig ist, kann man als weitere Regel einführen, dass am Anfang jeder
Datei das ESCAPE Zeichen angeführt wird.
Letztendlich würde diese Datei entstehen:
ublua(6)ub(3)ul(4)ua(2)
-> 15 Buchstaben (Bytes)
Originaltext: blaaaaaabbbllllaa -> 17 Buchstaben (Bytes)
Obwohl dieses Beispiel nicht wirklich die Vorteile des RLE Verfahrens hervorhebt,
zeigt es denoch die Vorgehensweise und Idee hinter dem Prinzip sehr gut. Auch
wenn es nun so scheinen mag, als hätte RLE keine Nutzen, so sei jedoch
erähnt, dass nicht nur reine Textdateien komprimiert werden sollen, sondern
zum Beispiel Bilddaten ohne komplexe Strukturen, die somit sich oft wiederholende
Bytefolgen beinhalten.
Huffmankomprimierung
Nun zur 2ten Methode mit der unser Tool Daten komprimiert. Wir werden hier
nur die dynamische Huffmankomprimierung behandeln, obwohl es noch die statische
und die adaptive gibt (Wer daran interessiert ist, möge sich bei unseren
weiterführenden Links (INFO Seite) weiterinfomieren). Ein wesentlicher
Unterschied ist, dass bei dieser Art die Häufigkeit jedes Zeichens eine
wichtige Rolle spielt. Das Grundprinzip ist dabei: die Zeichenhäufigkeiten
feststellen, dh. es wird eine Statistik erstellt, welches Zeichen wie oft vorkommt
und dann wird aufgrund dieser Statistik entschieden, welche Zeichen einen kurzen
Code bekommen sollen und welche einen längeren. Dabei sollte dem Leser
auch gleich auffallen, dass hierbei Codewörter mit unterschiedlichen Codewörtern
entstehen. Bei der Lauflängencodierung haben wir stets einen sogenannten
Blockcode benutzt. Dh. alle Codewörter besitzen die gleiche Länge
und somit kann leicht damit gearbeitet werden, da man stets weiß, wo ein
Codewort endet und ein anderes beginnt. Bei unseren neuen Codewörtern ist
das nicht so klar. Damit man die Codewörter überhaupt eindeutig unterscheidbar
sind, muss die Regel festgelegt werden, dass kein Codewort der Beginn eines
anderen Codeworts sein darf. Diese Definition entspricht der Definition eines
Prefixcodes.
Beispieltext:
Nur wer das Ziel kennt, kann es treffen.
Noch mal kurz zur Wiederholung unseres bisherigen Algorithmus:
- Datei durchlaufen und zählen, wie oft jedes Zeichen vorkommt. Nun sollte
eine Tabelle wie folgt entstehen:
| |
|
| N |
1 |
| u |
1 |
| r |
3 |
| Leerzeichen |
7 |
| w |
1 |
| e |
6 |
| d |
1 |
| a |
2 |
| s |
2 |
| Z |
1 |
| i |
1 |
| l |
1 |
| k |
2 |
| n |
5 |
| t |
2 |
| , |
1 |
| f |
2 |
| . |
1 |
| |
|
- Diese Tabelle soll nun nach der Zeichenhäufigkeit und dem Rang im Alphabet
geordnet werden.
| |
|
| 7 |
Leerzeichen |
| 6 |
e |
| 5 |
n |
| 3 |
r |
| 2 |
a |
| 2 |
f |
| 2 |
k |
| 2 |
s |
| 2 |
t |
| 1 |
, |
| 1 |
. |
| 1 |
N |
| 1 |
Z |
| 1 |
d |
| 1 |
i |
| 1 |
l |
| 1 |
u |
| 1 |
w |
| |
|
Alles rund um die Programmierung
Hier finden Sie genaue Informationen zum Code unseres Programms. Die Reihenfolge dieser Information ist durch die Codedateien bestimmt. Es wird also nicht in Programmausführungsrichtung gearbeitet.
Das Codesegment, das gerade erläutert wird, wird ebenfalls angegeben und hervorgehoben, um Ihnen das Leben leichter zu machen.
Achtung! Es können in den Binaries noch einige Tippfehler enthalten sein, die aber bei der genauen Durchsicht für folgende Dokumentation ausgebessert worden sind und den ordnungsgemäßen Ablauf des Programms nicht behindern. Sollten Sie in den Binaries auf Tippfehler stoßen, dann vergleichen Sie bitte mit folgender Dokumentation. Der Fehler ist in diesem Dokoument höchstwahscheinlich schon ausgebessert. Ist das nicht der Fall, dann teilen Sie uns diesen Bug bitte mit. Danke!
- Es werden Grundkenntnisse in der C-Programmierung vorausgesetzt.
Inhalt
Codedateien:
Headerdateien:
Codedateien
//***********************************************//
//Dateiname: nice_main.c
//Autor: Walter Scherer
//Projekt: niCE - nice insignificant compression engine
//Zweck: Parameterübergabe von Userseite
//Datum letzte Änderung: 01.06.2003
//***********************************************//
- Dieser Codeteil enthält nur Kommentar, der aber bei jeder Codedatei enthalten sein sollte, falls es im Rahmen der Configuration Identification keine Datenbank gibt, die diese Informationen speichert.
int temp_num_error=0;
- Diese Variable zählt Fehler, die in der Programmausführung aufgetreten sind. Die globale Definition macht es möglich aus jeder zum Projekt gehörenden Datei auf diese Variable zuzugreifen.
Variablen so lokal wie möglich, aber so global wie notwendig deklarieren.
#include "nice.h"
#include "huffman.h"
#include "parameter.h"
#include "globals.h"
#inlcude "rle.h"
- Notwendige Headerdateien inkludieren.
- Danach folgt der Funktionskopf der ersten Funktion (wird hier nicht angeführt). Ob Sie ihn innerhalb Ihrer Codedatei oder irgendwo außerhalb in einer Datenbank speichern, bleibt Ihnen überlassen. Sie sollten allerdings schnell darauf zugreifen können.
int check_target_extension(char *filename)
{
int run_a;
int run_b=0;
int start_position_extension=0;
int int_check_extension=0;
char *check_extension=REQUESTED_EXTENSION;
- Funktion zum Überprüfen der Erweiterung von filename auf Gleichheit mit REQUESTED_EXTENSION (definiert in huffman.h).
- run_a und run_b sind Laufvariablen.
- start_position_extension wird im weiteren Funktionsablauf die Stelle des Beginns der Dateierweiterung markieren. Diese muss ja erst gefunden werden.
- int_check_extension ist der Rückgabewert der Funktion. Wenn int_check_extension==0, ist die Erweiterung ok, ansonsten ist ein Fehler aufgetreten.
- check_extension speichert die gewünschte Dateierweiterung.
for (run_a=0;run_a<(int(strlen(filename);run_a++)
{
if ((filename[run_a])=='.')
{
start_position_extension=run_a+1;
}
}
- Die for-Schleife durchläuft den gesamten Dateinamen.
- Wird an irgendeiner Stelle im Dateinamen ein Punkt gefunden, so wird die Positionsvariable start_position_extension dementsprechend gesetzt (run_a+1 deswegen, weil Laufvariable bei 0 beginnt).
if ((strcmp(filename+start_position_extension, check_extension))!=0)
{
printf("extension of %s should be \"nice\".\n", filename);
temp_num_error++;
return 1;
}
return 0;
- Die Funktion strcmp(...) vergleicht zwei Strings auf Gleichheit und gibt 0 bei Gleichheit zurück.
- Wenn strcmp(...) nicht gleich 0, stimmt die Erweiterung (, die übrigens an filename+start_position_extension.Stelle liegt) nicht mit der spezifizierten Erweiterung überein. Deshalb wird die Fehlervariable um 1 erhöht und 1 zurückgegeben.
- Andernfalls stimmt die Erweiterung, es wird 0 zurückgegeben.
- BEMERKUNG: Hier müsste man theoretisch das fix codierte \"nice\" in der printf-Anweisung gegen die Variable check_extension tauschen.
void usage()
- Es folgt die Funktion, die die Benutzungshinweise zum Programm wiedergibt. Da diese Funktion selbsterklärend ist, wird sie hier nicht seziert.
int check_parameters_main (int argc, char *argv[])
{
char *file_source;
char *file_target;
char *temp_filename;
double size_source;
double size_target;
int temp_check_valid=0;
int temp_get_parameter;
- Diese Funktion liest die Parameter ein und wertet sie aus. Aus diesem Grund wird ihr sowohl argc als auch argv übergeben.
- file_source wird zum Speichern des Quelldateinamens verwendet
- file_target wird zum Speichern des Zieldateinamens verwendet
- temp_filename bezeichnet die temporäre Datei, die zwischen den beiden Codierungsalgorithmen (RLE und Huffman) übergeben wird.
- size_source bezeichnet die Größe der Quelldatei.
- size_target bezeichnet die Größe der Zieldatei.
- Die beiden zuletzt genannten Variablen sind notwendig, damit das Programm überprüfen kann, ob die Zieldatei tatsälich kleiner als die Quelldatei ist (vor allem bei Komprimierung interessant). Ist sie das nicht, wird eine Warnung ausgegeben.
- temp_check_valid bestimmt, ob die Parameter richtig eingegeben worden sind. Bei 0 liegt ein Fehler vor, bei 1 stimmt die Eingabe. Ob die Eingabe stimmt oder nicht, hängt davon ab, ob der User dem Parameter ein '-' vorangeschickt hat.
- temp_get_parameter enthält den eigentlichen Parameterbuchstaben (c)
while ((--argc > 0) && (**++argv == '-'))
- Diese Anweisung lässt das Programm die vom User eingegebenen Parameter durchlaufen.
- 1. Bedingung: --argc > 0: Die while-Schleife wird genau so oft durchlaufen wie es Parameter gibt.
- 2. Bedingung: **++argv == '-': Überprüft, ob der nächste Parametereintrag im Argumentvektor mit einem '-' beginnt. Beachten Sie dabei, dass der Argumentvektor immer um ein Element weitergeschoben wird.
temp_check_valid = 1;
while (temp_get_parameter = *++argv[0])
{
switch (temp_get_parameter)
- Parametereingabe ist korrekt, daher temp_check_valid = 1.
- Die while-Anweisung sorgt nun dafür, dass alle hinter dem '-' stehenden Buchstaben aus der Kommandozeile jetzt interpretiert werden können. temp_get_parameter wird jetzt mit jedem Buchstaben, der dem '-' nachfolgt, belegt. Beachten Sie, dass dies nur bis zum Leerzeichen erfolgt (argv[0]) und nicht darüber hinaus. Aus diesem Grund mißversteht das Programm eine derartige Eingabe: nice -c -s. -s steht in diesem Fall in argv[1]!
- Abhängig von dem eingebenen Parameter (oder von den eingegbenen Parametern) entscheidet das Programm, was zu tun ist (switch).
case 'c':
file_source=argv[1];
file_target=argv[2];
if ((file_source==NULL) || (file_target==NULL))
{
printf("an parameter error occurred. you probably forgot to specify the files.\n");
temp_num_error++;
break;
}
- Falls ein 'c' als Parameter eingegeben worden ist, startet das Programm den Versuch die angegebene Datei zu komprimieren.
- Dazu wird der Name der Quelldatei eingelesen und in file_source gespeichert, und es wird der Name der Zieldatei eingelesen und in file_target gespeichert.
- Die if-Anweisung prüft, ob zwei Dateien nach dem Parameter eingegeben worden sind. Falls nicht, erhöht das Programm die globale Fehlervariable temp_num_error um 1 und verlässt die while-Schleife.
if (check_target_extension(file_target)==1)
break;
- Sollte die Erweiterung der Zieldatei nicht der Norm entsprechen (die Funktion check_target_extension(...) gibt in diesem Fall 1 zurück), wird die while-Schleife ebenfalls verlassen.
if ((file_source!=NULL)&&(file_target!=NULL))
{
printf("coding procedure in progress. source: %s, target: %s.\n\nplease wait...\n", file_source, file_target);
printf("rle - coding procesure in progress.\n");
file_source= rle_cod(file_source);
printf("huffman - coding procedure in progress.\n");
control_coding(file_source, file_target);
remove(file_source);
}
else
{
printf("You have to specify the source file and then the target file after parameter '-c'\n");
temp_num_error++;
}
break;
- Die if-Schleife prüft, ob der Benutzer auch wirklich mindestens 2 Dateien hinter dem Parameter '-c' eingegeben hat.
- Ist das der Fall informiert das Programm über den Programmfortschritt, wobei zunächst die RLE-Komprimierung angewandt wird (Funktion rle_cod(char *)) und dann die Huffman-Komprimierung (Funktion control_coding(char *, char *)).
- Die RLE-Komprimierungsfunktion übernimmt die vom Benutzer eingegebene Quelldatei (file_source) und überschreibt den char * (Name der Quelldatei file_source) mit dem Namen der temporären RLE-komrimierten Datei. Wichtig! Die Quelldatei selbst wird natürlich nicht überschrieben.
- Danach übernimmt die Huffman-Komprimierung, wobei diese Funktion auch das Erstellen der Zieldatei (file_target) übernimmt.
- Die remove(char *)-Funktion entfernt die temporär erstellte Datei der RLE-Komprimierung. Für nähere Informationen zu temporären Dateien, lesen sie bitte bei den RLE-Sourcedateien weiter.
case 'd':
- Es folgt der Abschnitt für die Dekomprimierung der Datei.
file_source=argv[1];
file_target=argv[2];
if ( (temp_filename = _tempnam("c:\\", "nice_tmp" ) ) == NULL )
{
printf( "Cannot create a unique filename\n" );
return 1;
}
- Belegen der char * mit den entsprechenden Parametern. file_source ist die Quelldatei und file_target ist die Zieldatei.
if ((file_source != NULL) && (file_target != NULL) && (temp_filename != NULL))
{
printf("decoding procedure in progress. please wait...\n");
printf("decoding huffman-encoded data. please wait...\n");
DecompressFile(file_source, temp_filename);
printf("decoding rle-encoded data. please wait...\n");
rle_dcod(temp_filename, file_target);
printf("decoding procedure finished.\n");
remove(temp_filename);
}
- Die if-Schleife überprüft, ob vom Benutzer die komprimierte Datei und die Zieldatei angegeben wurde und ob das System eine temporäre Datei anlegen konnte. Die temporäre Datei speichert die Bitfolge nach Huffman-Decodierumg ab und wird bei der RLE-Decodierung als Quelldatei hergenommen.
- Die Funktion DecompressFile(char *, char *) führt die Huffman-Decodierung durch. Sie nimmt die vom Benutzer angegebene (komprimierte) Quelldatei her (file_source) und schreibt das Ergebnis in die temporäre Datei (temp_filename).
- Die Funktion rle_dcod(char *, char *) - von den Parametern her gleicht diese Funktion der Huffman-Decodierung, sie übernimmt als ersten Parameter die Quelldatei und als zweiten Parameter die Zieldatei - führt die RLE-Decodierung durch.
- Nähere Informationen zu den Funktionen der Decodierung in den entsprechenden Quelldateien.
- Die Funktion remove(char *) ist eine Bibliotheksfunktion von ANSI-C und löscht temporär angelegte Dateien, wobei der Dateiname der temporären Datei übergeben wird.
else
{
printf("You have to specify source file and then target file after parameter 'd'\n");
temp_num_error++;
}
break;
- Falls entweder Zieldatei oder Quelldatei vom Benutzer nicht angegeben worden sind, wird eine Fehlermeldung ausgegeben und die globale Fehlervariable temp_num_error um 1 erhöht.
case 's':
file_source=argv[1];
if (file_source==NULL)
{
printf("please specify at least one file after parameter 's'\n");
temp_num_error++;
break;
}
- Zunächst wird der nach dem Parameter 's' eingegebene Dateinamen in file_source gespeichert.
- Danach wird mittels if-Schleife überprüft, ob der Benutzer überhaupt eine Datei eingegeben hat. Wenn nicht, wird die globale Fehlervariable wieder um 1 erhöht. break; verläßt die switch-Anweisung.
size_source=start_general_statistics(file_source);
if ((file_target=argv[2])!=NULL)
{
size_target=start_general_statistics(file_target);
if (size_target>size_source)
printf("WARNING: target file is bigger than source file.\n");
calc_coding_percentage(size_source, size_target);
}
break;
- Die Funktion start_general_statistics(char *) berechnet Kenngrößen der angegebenen Datei und gibt diese aus. Nähere Informationen in der Statistikquelldatei. Außerdem gibt die Funktion die Dateigröße zurück.
- Wenn dem Parameter 's' nur ein Parameter folgt, wird die Statistik dieser einen Datei berechnet, und damit beläßt es das Programm.
- Gibt es aber noch eine weitere Datei (die if-Schleife überprüft), wird auch die Statistik dieser Datei ausgegeben.
- Zusätzlich werden dann noch die beiden Größen der Dateien verglichen, wobei eine Warnung ausgegeben wird, wenn die Dateigröße der Zieldatei größer ist als die der Quelldatei. Dies kann gewünscht (bei der Dekompression) oder unerwünscht sein (bei der Kompression).
default:
- Es folgt die Behandlung aller anderen (ungültigen) Parameter.
printf("nice: illegal option %c\n", temp_get_parameter);
temp_num_error++;
break;
}
- Bei allen anderen Parametern wird eine Fehlermeldung ausgegeben und die globale Fehlervariable um 1 erhöht.
if (temp_check_valid == 0)
{
usage();
return 1;
}
- Die Bedingung dieser if-Schleife ist dann erfüllt, wenn die Parameterangabe falsch war (wenn zB das '-' vor dem Parameter vergessen wurde). Aus diesem Grund ist es gut hier die Benutzungsinformationsfunktion usage() aufzurufen.
- Das Programm wird fehlerhaft beendet, dh. die Hauptfunktion bekommt eine 1 zurück.
switch (temp_num_error)
{
case 0:
printf("\nprogram finished.\n");
return 0;
break;
case 1:
printf("\n%d error occurred. Program terminated.\n", temp_num_error);
usage();
return 1;
break;
default:
printf("\n%d errors occurred. Program terminated.\n", temp_num_error);
usage();
return 1;
}
- In diesem Codestück wird abhängig von der Fehleranzahl temp_num_error eine Meldung ausgegeben, wobei temp_num_error==0 bedeutet, dass kein Fehler aufgetreten ist.
- Ist kein Fehler aufgetreten, wird an die aufrufende Funktion eine 0 zurückgegeben, ansonsten eine 1.
void main (int argc, char *argv[])
{
int temp_check_parameters = check_parameters_main(argc,argv);
}
- Es folgt die main-Funktion, die nichts anderes tut, als die Argumenteanzahl (argc) und den Argumentevektor (argv) einzulesen und an die Parameterprüffunktion weiterzugeben.
Top
Walter Scherer
statistics.c
- Der Dateikopf entspricht dem in unserem Projekt üblichen Vorgaben. Für die inkludierten Headerdateien bitte hier nachsehen.
- Die Headerdateien befinden sich von dieser Datei aus gesehen im übergeordneten Verzeichnis, daher ..
void calc_coding_percentage(double size_source, double size_target)
- Die Funktion calc_coding_percentage(double, double) berechnet das Verhältnis zwischen Größe zweiter Datei und erster Datei
double coding_percentage=0.;
coding_percentage=((100*size_target)/size_source);
printf("\tcode rate: \t\t\t%lf%%\n", coding_percentage);
- Berechnung der Code-Rate (in Prozent)
void calc_avg_length_of_code(BitSequence *pt_array_codetable)
- Diese Funktion berechnet die durchschnittliche Länge des Codes
- Diese Länge ist im Array pt_array_codetable gespeichert
- Für die Struktur BitSequence bitte in huffman.h nachsehen
int run_a;
float avg_code_length=0.;
int counter=0;
int num_crucial_chars=0;
- run_a ist Laufvariable
- avg_code_length speichert das Endergebnis (die durchschnittliche Codelänge)
- counter speichert die Summe der Codelängen
- num_crucial_chars speichert die Anzahl der vorkommenden Zeichen
for (run_a=0; run_a<256; run_a++)
{
if ((pt_array_codetable[run_a].length)!=0)
{
num_crucial_chars++;
counter=counter+((int)(pt_array_codetable[run_a].length));
}
}
avg_code_length=((float)counter/(float)num_crucial_chars);
printf("\taverage length of code: \t\t\t%lf\n", avg_code_length);
- Die for-Schleife durchläft alle 256 ASCII-Zeichen (entspricht der Position im Array)
- Die if-Schleife überprüft, ob ein Zeichen überhaupt vorkommt. Wenn nicht, wird dem Zeichen natürlich kein Code zugewiesen, dh. Code-Länge (pt_array_codetable[run_a]).length ist 0
- Kommt ein Zeichen vor, wird die Variable num_crucial_chars um 1 erhöht
- Außerdem wird die jeweilige Länge des Codes zur Gesamtlänge dazugezählt
double start_general_statistics(char *filename)
- Diese Funktion startet die Statistikberechnung mit Bildschirmausgabe und gibt die Größe der durch den Parameter filename spezifizierten Datei zurück
int num_chars;
double size_file;
printf("-------------------------------------------------------------\n");
printf("\t\tfile statistics: file %s\n", filename);
printf("-------------------------------------------------------------\n");
num_chars=get_number_of_chars(filename);
size_file=get_size_of_file(filename, num_chars);
printf("-------------------------------------------------------------\n");
return size_file;
- num_chars ist eine Zwischenspeicherungsvariable für die Anzahl der Zeichen
- size_file ist eine Zwischenspeicherungsvariable für die Größe der Datei filename
- get_number_of_chars(char *) besorgt sich die Anzahl der Zeichen in einer Datei
- get_size_of_file(char *, int) besorgt sich die Größe der Datei (Parameter 1)
int get_number_of_chars(char *filename)
- get_number_of_chars(char *) zählt die Zeichen in einer Datei
FILE *pt_file;
char temp_char;
int temp_number=0;
if ((pt_file=open_file_read_access(filename))==NULL)
{
printf("an error occurred when trying to retrieve file statistics.\n");
return -1;
}
- temp_char bezeichnet den gerade ausgelesenen Buchstaben
- temp_number speichert die Anzahl der ausgelesenen Zeichen
- Die if-Schleife überprüft, ob das System die Datei öffnen kann (s. open_file_read_access)
while ((temp_char=getc(pt_file)!=EOF))
temp_number++;
- Durch die Funktion getc(FILE *) wird der Filepointer immer um ein Zeichen weitergeschoben
-
- Die while-Schleife wird erst am Ende der Datei verlassen
- Für jedes Zeichen wird temp_num um 1 erhöht
fclose(pt_file);
printf("\ttotal number of characters:\t\t\t%d\n", temp_number);
return temp_number;
- Danach wird die Datei geschlossen und die Anzahl der Zeichen ausgegeben
- Außerdem liefert die Funktion die Anzahl an ausgelesenen Zeichen zurück
double get_size_of_file(char *filename, int num_chars)
- Diese Funktion liefert die Größe der angegebenen Datei und berechnet die Entropie (aus diesem Grund wird auch die Zeichenanzahl übergeben)
struct stat stbuf;
if (stat(filename, &stbuf) == -1)
{
fprintf(stderr, "nice: cannot access %s\n", filename);
return -1;
}
- stat stbuf ist die Speicherstruktur für die Dateiinformationen
- Die Funktion stat(char *, &stat) belegt die Struktur mit den Dateiinformationen. Sie liefert -1 zurück, falls der Zugriff auf die angegebene Datei nicht möglich ist
printf("\tsize of file: \t\t\t\t\t%ld Bytes\n", stbuf.st_size);
calc_entropy(filename, num_chars);
return stbuf.st_size;
void calc_entropy(char *filename, int num_chars)
- Diese Funktion berechnet die Entropie der Datei, deren Name der Funktion übergeben wird
int run_a;
int num_crucial_chars=0;
double *pt_array_probability;
double entropy=0.;
pt_array_probability=huffman_analyse_program(filename);
- run_a ist eine Laufvariable
- num_crucial_chars enthält am Ende der Funktion die Anzahl der unterschiedlichen Zeichen
- pt_array_probability wird im Laufe der Funktion mit den Zeichenwahrscheinlichkeiten - geordnet nach ASCII-Code - belegt wird (Funktion: huffman_analyse_program(char *))
- entropy ist der Entropiewert, der gleich initialisiert wird
for (run_a=0;run_a<256;run_a++)
{
if (pt_array_probability[run_a]!=0.)
{
num_crucial_chars++;
pt_array_probability[run_a]=(pt_array_probability[run_a]*((log(1/pt_array_probability[run_a]))/log(2.)));
entropy=entropy+pt_array_probability[run_a];
}
}
- Das schon belegte Array mit den Wahrscheinlichkeitswerten wird in dieser for-Schleife untersucht (aus diesem Grund läuft run_a bis 256 (Maximaler ASCII-Wert))
- Die if-Schleife überprüft, ob das aktuelle Zeichen in der Datei überhaupt vorkommt, d.h. ob die Wahrscheinlichkeit eines Zeichens nicht 0 ist. Ist die Bedingung der if-Schleife erfüllt, liegt ein num_crucial_chars vor, d.h. ein in der Datei vorkommendes Zeichen. Daher wird num_crucial_chars um 1 inkrementiert
- Gleichzeitig wird die aktuelle Position im Array mit dem errechneten Entropiewert überschrieben, da die Wahrscheinlichkeiten nach der Entropieberechnung nicht mehr benötigt werden
- Die Formel der Entropie bitte in der Fachliteratur nachschlagen, es sei allerdings hier ein kleiner Hinweis angegeben: Will man den Entropiewert standardisieren ("zwischen 0 und 1 ausrechnen"), darf man nicht durch log(2.) dividieren, sondern durch log((double)num_crucial_chars). Dazu müßte man die Bestimmung der vorkommenden Zeichen jedoch vor und nicht während der Entropieberechnung durchführen
- Die Summe der einzelnen Entropiewerte bildet den gesuchten Gesamtentropiewert
printf("\tentropy: \t\t\t\t\t%.10lf Bit\n", entropy);
printf("\tnumber of different characters: \t\t%d\n", num_crucial_chars);
FILE *open_file_read_access(char *filename)
- Diese Funktion öffnet die als Parameter angegebene Datei und gibt NULL bei Fehler zurück
FILE *pt_file;
if ((pt_file=(fopen(filename, "rb")))==NULL)
{
printf("nice: could not open file.\n");
temp_num_error++;
return NULL;
}
return pt_file;
- Es wird die C-Bibliotheksfunktion fopen(char *, char *) verwendet, die den Filepointer (hier: pt_file) auf den Beginn des Dateistreams setzt. Bei Fehler liefert die Funktion NULL zurück
Top
Walter Scherer
start_and_control_coding.c
- Der Dateikopf entspricht dem in unserem Projekt üblichen Vorgaben. Für die inkludierten Headerdateien bitte hier nachsehen.
- Die Headerdateien befinden sich von dieser Datei aus gesehen im übergeordneten Verzeichnis, daher ..
void control_coding(char *file_source, char *file_target)
- Die Funktion control_coding führt das Programm durch die Huffman-Komprimierung, wobei der erste Parameter die zu komprimierende Datei ist und der zweite die Zieldatei
- Diese Funktion ist der einzige Inhalt dieser Source-Datei
double *pt_array_probabilities;
Node *pt_root_node;
BitSequence *pt_array_codetable;
- pt_array_probabilities ist für die Wahrscheinlichkeiten der ASCII-Zeichen in der Quelldatei vorgesehen
- pt_root_node ist für den Wurzelknoten des Huffman-Baums reserviert
- pt_array_codetable wird den für jedes ASCII-Zeichen erstellten Code enthalten
printf("analysing %s...\n", file_source);
pt_array_probabilities=huffman_analyse_program(file_source);
if (pt_array_probabilities==NULL)
{
printf("\nnice:coding_control: An error occurred while trying to analyse file for huffman code.\n");
temp_num_error++;
return;
}
- Die Funktion huffman_analyse_program(char *) analysiert die Quelldatei und schreibt die Zeichenwahrscheinlichkeiten geordnet nach ASCII-Code in pt_array_probabilities
printf("creating huffman tree...\n");
pt_root_node=CreateTree(pt_array_probabilities);
if (pt_root_node==NULL)
{
temp_num_error++;
printf("\nnice:coding_control: an error occurred while trying to build huffman tree.\n");
return;
- Nun wird der Huffman-Baum erstellt. Für genauere Informationen zum Thema Huffman-Codierungstheorie bitte sich im Abschnitt Info oder in der Fachliteratur zu informieren
- Die Funktion zur Erstellung des Huffman-Baumes ist CreateTree(BitSequence *), die ein Wahrscheinlichkeitsarray verlangt und den Wurzelknoten des erstellten Baumes zurück gibt
- Kann der Huffman-Baum aus irgendeinem Grund nicht erstellt werden, gibt die Funktion NULL zurück. Das wird nach dem Funktionsaufruf in der if-Schleife überprüft
- Im Fehlerfall wird - wie immer - eine Meldung ausgegeben und die globale Fehlervariable temp_num_error um 1 erhöht
printf("creating coding table...\n");
pt_array_codetable=CreateCodingTable(pt_root_node);
if (pt_array_codetable==NULL)
{
printf("\nnice:coding_control: could not establish code table.\n");
temp_num_error++;
return;
}
- Nun wird die Codierungstabelle erstellt (die Zuweisungstabelle Zeichen-Code)
- Dazu wird die Funktion CreateCodingTable(Node *) verwendet, die aus dem Wurzelknoten des Huffman-Baumes eine Codiertabelle erstellt und diese zurückgibt
- Nach Funktionsaufruf wird überprüft, ob die Funktion korrekt ausgeführt werden konnte. Wenn nicht gibt sie NULL zurück. Eine Fehlermeldung wird ausgegeben
calc_avg_length_of_code(pt_array_codetable);
printf("saving data to %s....\n", file_target);
OpenFiletoSave(file_source, file_target, pt_root_node, pt_array_codetable, 1);
printf("completing algorithm...\n\n");
DestroyTree(pt_root_node);
DestroyCodingTable(pt_array_codetable);
Top
Walter Scherer
huffman_analyse.c
- Der Dateikopf entspricht dem in unserem Projekt üblichen Vorgaben. Für die inkludierten Headerdateien bitte hier nachsehen.
- Die Headerdateien befinden sich von dieser Datei aus gesehen im übergeordneten Verzeichnis, daher ..
void calc_probability(int temp_counter, double *pt_array_probability)
- Diese Funktion rechnet für ein übergebenes Array mit Absolutwerten die Wahrscheinlichkeiten bezogen auf temp_counter aus
int run_a;
for (run_a=0;run_a<256;run_a++)
{
pt_array_probability[run_a]=(pt_array_probability[run_a]/temp_counter);
}
- run_a ist Laufvariable für die for-Schleife
- Die folgende for-Schleife berechnet die relative Häufigkeiten jedes Zeichens, wobei temp_counter die Gesamtanzahl der Zeichen darstellt
- Die alten Array-Einträge (absolute Zahlen) werden mit den relativen Häufigkeiten überschrieben
void count_char(int temp_character, double *pt_array_probability)
- Diese Funktion zählt das übergebene Zeichen und erhöht den vom Zeichen vorgegebenen Platz im Array (ASCII-Code)
(*(pt_array_probability+temp_character))++;
- Zunächst wird die richtige Stelle im Array gesucht (pt_array_probability+temp_character). Da pt_array_probability ein - wie der Name schon vermuten läßt - Pointer ist, kann man ganz normal mit diesem Pointer rechnen. Zählt man den ASCII-Code eines Zeichens zur Startposition des Vektors, kommt man auf den richtigen Eintrag
- Der richtige Eintrag wird dann lediglich um eins erhöht, wobei der Dereferenzierungsoperator (*) vor der Berechnung pt_array_probability+temp_character. Es soll ja der Wert, auf den diese Pointer-Berechnung zeigt, um 1 erhöht werden und nicht die Adresse
double *huffman_analyse_program(char *file)
- Das ist die Hauptfunktion, die die Analyse der angegebenen Datei startet
- Rückgabewert ist das ausgearbeitete Array mit den relativen Wahrscheinlichkeitswerten
FILE *pt_file=NULL;
int temp_character;
int temp_counter=0;
int run_a;
double *pt_array_probability=(double *)malloc(sizeof(double)*256);
- pt_file bezeichnet den Pointer auf die zu öffnende Datei (file)
- temp_character stellt das gerade ausgelesene Zeichen dar
- temp_counter zählt jedes vorkommende Zeichen
- run_a ist Laufvariable
- pt_array_probability ist für das Wahrscheinlichkeitsarray vorgesehen. Es wird gleich Speicherplatz reserviert und zwar für jedes ASCII-Zeichen (256) eine double-Variable
for (run_a=0;run_a<256;run_a++)
pt_array_probability[run_a]=0;
- In dieser for-Schleife wird jeder Arrayeintrag initialisiert (auf 0 gesetzt), um das einwandfreie Funktionieren des Programms zu gewährleisten
if ((pt_file=fopen(file, "rb"))==NULL)
{
fprintf(stderr, "huffman_analyse: cannot open file\n");
return NULL;
}
else
{
while ((temp_character=getc(pt_file))!=EOF)
{
temp_counter++;
count_char(temp_character, pt_array_probability);
}
}
- Zunächst wird die angegebene Datei geöffnet, wobei dafür die Funktion fopen(char *, char *) verwendet wird (Näheres in jeder guten C-Sprachendokumentation)
- Hat das Öffnen der Datei funktioniert, wird jedes Zeichen in der Datei überprüft (while-Schleife). Jedes Zeichen wird (samt zu befüllendem Array) der Funktion count_char(int, double *) übergeben und dort gezählt
- Das jeweilige Zeichen wird mit Hilfe der C-Funktion getc(FILE *) aus der Datei eingelesen, wobei sich diese C-Funktion bei jedem Aufruf auch um die Weiterschiebung des File-Pointers kümmert. Das eingelesene Zeichen wird zurückgeben
- Ist das Ende der Datei erreicht, gibt die Funktion die Variable EOF zurück
calc_probability(temp_counter, pt_array_probability);
fclose(pt_file);
return pt_array_probability;
- Für die Funktion calc_probability(int, double *) bitte hier nachsehen
- Abschließend wird die Datei mittels C-Funktion fclose(FILE *) geschlossen und das befüllte Wahrscheinlichkeitsarray zurückgegeben
Top
Walter Scherer
save_tree.c
- Der Dateikopf entspricht dem in unserem Projekt üblichen Vorgaben. Für die inkludierten Headerdateien bitte hier nachsehen.
- Die Headerdateien befinden sich von dieser Datei aus gesehen im übergeordneten Verzeichnis, daher ..
BitSequence SaveTree(FILE *pt_file, Node *pt_RootNode, BitSequence BufferBitSequence)
- Diese Funktion übersetzt den Huffman-Baum in speicherbare BitSequences (der Huffman-Baum ist bereits aufgebaut)
TraverseTreeforSave(pt_RootNode, "", &SaveNodetoFile, &BufferBitSequence, pt_file);
return BufferBitSequence;
- Diese Funktion läuft den Baum durch und veranlaßt das Abspeichern des Baumes
- Aus programmiertechnischen Gründen gibt die Funktion am Ende des Abspeicherungsvorgangs meistens noch eine BitSequence zurück, die dann später noch berücksichtigt wird
void OpenFiletoSave(char *file_name_source, char *file_name_target, Node *pt_RootNode, BitSequence *pt_array_codetable, char Continue)
- Diese Funktion erhält als Parameter sowohl den Dateinamen der Ursprungsdatei (file_name_source) als auch den Dateinamen der Zieldatei (file_name_target), um das Speichern der codierten Bitsequenz zu beginnen
- Außerdem werden der Wurzelknoten des Baumes (pt_RootNode) und die Codiertabelle (pt_array_codetable) als Quellen übergeben
- Der char Continue ist aus programmiertechnischen Gründen für die Funktion CompressFile(FILE *, FILE*, BitSequence *, BitSequence, char) relevant und wird in dieser Funktion nur durchgereicht
FILE *pt_file_source;
FILE *pt_file_target;
BitSequence BufferBitSequence;
int temp_code=0;
BufferBitSequence.length=0;
BufferBitSequence.Code=&temp_code;
- pt_file_source bzw. pt_file_target sind Filepointer auf die Quell- bzw. Zieldatei
- BufferBitSequence wird nach Aufruf der Funktion SaveTree(FILE *, Node *, BitSequence) mit dem Rest der BitSequence (so es einen gibt) belegt
- Hinweis: In die Zieldatei wird immer nur eine Bitfolge mit Länge 8 gespeichert. Bleibt der Funktion SaveTree(FILE *, Node *, BitSequence) und ihren Subfunktionen jedoch am Schluss des Bitstreams zwischen 1 und 7 Bit inklusive über, so muss sich die Funktion CompressFile(FILE *, FILE*, BitSequence *, BitSequence, char) um die Speicherung der verbleibenden Bits kümmern
- Die Funktion SaveTree(FILE *, Node *, BitSequence) verlangt eine initialisierte BitSequence. Das erklärt die nächsten 3 Zeilen des Codes, die nichts anderes tun, als BufferBitSequence mit Code 0, Länge 0 zu initialisieren
if (((pt_file_source=(fopen(file_name_source, "rb")))==NULL) || ((pt_file_target=(fopen(file_name_target, "wb")))==NULL))
{
printf("huffman:save_tree.c: could not open files.\n");
temp_num_error++;
return;
}
- Anschließend wird versucht die Quelldatei zum Lesezugriff und die Zieldatei zum Schreibzugriff zu öffnen. Wichtig ist das b für "binary", um das korrekte Lesen bzw. Schreiben zu ermöglichen
- Zum Öffnen der Dateien wird die C-Bibliotheksfunktion fopen(char *, char *) verwendet, bei Interesse an dieser Funktion in geeigneter Fachliteratur Informationen einholen
BufferBitSequence=SaveTree(pt_file_target, pt_RootNode, BufferBitSequence);
CompressFile(pt_file_source, pt_file_target, pt_array_codetable, BufferBitSequence, Continue);
fclose(pt_file_source);
fclose(pt_file_target);
Top
Walter Scherer
Headerdateien
globals.h
#ifndef COUNTER_ERROR
#define COUNTER_ERROR
extern int temp_num_error;
#endif
- Es wird die globale Fehlervariable temp_num_error definiert. Das extern gibt an, dass die Variable schon in einer anderen Datei definiert wurde und verhindert eine Neuanlage der Variable
#ifndef STATISTICS
#define STATISTICS
double start_general_statistics(char *filename);
double get_size_of_file(char *filename, int num_chars);
int get_number_of_chars(char *filename);
void calc_entropy(char *filename, int num_chars);
FILE *open_file_read_access(char *filename);
void calc_avg_length_of_code(BitSequence *pt_array_codetable);
void calc_coding_percentage(double size_source, double size_target);
#endif
Top
Walter Scherer
huffman.h
#ifndef HUFFMAN_FUNCTIONS
#define HUFFMAN_FUNCTIONS
#define CHAR_LENGTH 1
#define INT_LENGTH 1
#define LEFT 0
#define RIGHT 1
#define REQUESTED_EXTENSION "nice"
#define LENGTH_OF_EXTENSION 4
#define LEAFNODE 1
#define ROOTNODE 0
- Die Konstanten LEFT und RIGHT werden mit 0 bzw. 1 initialisiert, um die linken bzw. rechten Kinder eines Knotens im Huffman-Baum anschaulich und bequem ansprechen kann
- REQUESTED EXTENSION gibt vor, wie die Erweiterung der Zieldatei auszusehen hat. Ändern Sie die Erweiterung, so müssen Sie darauf achten, dass die Angabe der Länge der Erweiterung in der Zeile darunter (LENGTH_OF_EXTENSION) mit Ihrer Angabe übereinstimmt ("nice" hat 4 Buchstaben, daher Länge 4)
typedef struct _Node
{
unsigned char cContent;
double ldProbability;
int iSimpleNode;
struct _Node *pt_Up;
struct _Node *pt_Down[2];
struct _Node *pt_Next;
} Node;
- Diese Struktur dient zum Darstellen der Knoten des Huffman-Baums. Sie enthält:
- cContent (Inhalt des jeweiligen Knotens)
- ldProbability (Wahrscheinlichkeit des Auftretens dieses Buchstabens (bei Blattknoten ist Buchstabe angegeben durch cContent) bzw. der Summe aller darunter liegenden Knoten, wenn Knoten kein Blattknoten ist)
- iSimpleNode (Informationsinteger: Ist Knoten ein Blattknoten, dann ist iSimpleNode 1, ansonsten 0)
- *pt_Up (Pointer auf den Vaterknoten)
- *pt_Down (Pointer auf das linke und rechte Kind des Knotens (Es handelt sich um einen Binärbaum!))
- *pt_Next (Pointer auf den Listennachbarn)
- Die Struktur bekommt einen Alias-Namen Node statt _Node
typedef struct
{
unsigned int *Code;
unsigned char length;
} BitSequence;
- Diese Struktur dient zum Darstellen der Bit Sequenz (des Codes). Sie enthält:
- *Code (Pointer auf die Codefolge)
- length (Länge des Codes)
- Die Struktur bekommt den Namen BitSequence
void control_coding(char *file_source, char *file_target);
void calc_probability(int temp_counter, double *pt_array_probability);
void count_char(int temp_character, double *pt_array_probability);
double *huffman_analyse_program(char *file);
Node *CreateTree(double *pt_array_Probabilities);
Node *CreateTreeFromFile(FILE *pt_File, BitSequence *pt_BufferSequence);
Node *CreateList (double *pt_array_Probabilities);
Node *CreateNode (int iSimpleNode, char cContent, double ldProbability, Node *pt_Up, Node *pt_DownLeft, Node *pt_DownRight, Node *pt_Next);
Node *InsertNode (Node *pt_BeginOfList, Node *pt_InsertNew);
void DestroyTree(Node *pt_rootNode);
void TraverseTree(Node *pt_RootNode, char *Depth, void (*ManipulateNode)(Node *pt_ActualNode, char *Depth, void *pt_ExtraData), void *pt_ExtraData);
void TraverseTreePreorder(Node *pt_RootNode, char *pt_Depth, void (*ManipulateNode)(Node *pt_ActualNode, char *pt_Depth, void *pt_ExtraData), void *pt_ExtraData);
void TraverseTreeforSave(Node *pt_RootNode, char *pt_Depth, void (*ManipulateNode)(Node *pt_ActualNode, char *pt_Depth, void *pt_ExtraData, FILE *pt_file), void *pt_ExtraData, FILE *pt_file);
void TraverseTreeforRead(Node *pt_RootNode, char *pt_Depth, void (*ManipulateNode0)(Node *pt_ActualNode, char *pt_Depth, void *pt_ExtraData, FILE *pt_file) , void (*ManipulateNode1)(Node *pt_ActualNode, char *pt_Depth, void *pt_ExtraData, FILE *pt_file), void *pt_ExtraData, FILE *pt_file);
void ReadLeftChildFromFile (Node *pt_ActualNode, char *pt_Depth, void *pt_ExtraData, FILE *pt_file);
void ReadRightChildFromFile (Node *pt_ActualNode, char *pt_Depth, void *pt_ExtraData, FILE *pt_file);
void DeleteNode(Node *pt_ActualNode, char *Depth, void *pt_ExtraData);
void AddNodeToCodingTable(Node *pt_ActualNode, char *Depth, void *pt_ExtraData);
void SaveNodetoFile(Node *pt_ActualNode, char *pt_Depth, void *pt_ExtraData, FILE *pt_file);
#define MEMSIZE(BitLength) ((BitLength) % (sizeof(int) * 8) == 0 ? (char)((BitLength) / (sizeof(int) * 8)) : (char)((BitLength) / (sizeof(int) * 8) + 1))
int CreateBitSequence (char *pt_String, BitSequence *pt_GeneratedCode);
double PowerOf (long base, int exponent);
int IsBitSet (int CheckSequence, char CheckBitNr);
void ShiftLeft(BitSequence *ActualBitSequence);
int IsBitSetOfBS (BitSequence CheckSequence, unsigned char CheckBitNr);
BitSequence *CreateCodingTable (Node *pt_RootNode);
void DestroyCodingTable (BitSequence *pt_array_CodingTable);
void CompressFile (FILE *pt_FileUncompressed, FILE *pt_FileCompressed, BitSequence *pt_array_CodingTable, BitSequence BufferBitSequence, char Continue);
void DecompressFile (char *file_source, char *file_target);
int WriteBitSequenceToFile(FILE *pt_file, BitSequence *pt_BufferBitSequence, BitSequence *pt_ActualBitSequence);
char GetBitFromFile(FILE *pt_File, BitSequence *pt_BufferSequence);
char GetByteFromFile(FILE *pt_File, BitSequence *pt_BufferSequence);
int GetBitsequenceFromFile(FILE *pt_File, BitSequence *pt_BufferSequence);
BitSequence SaveTree(FILE *pt_file, Node *pt_RootNode, BitSequence BufferBitSequence);
void OpenFiletoSave(char *file_name_source, char *file_name_target, Node *pt_RootNode, BitSequence *pt_array_codetable, char Continue);
#endif
- void control_coding(char *, char *)
- void calc_probability(int, double *)
- void count_char(int, double *)
- double *huffman_analyse_program(char *)
- Node *CreateTree(double *)
- Node *CreateTreeFromFile(FILE *, BitSequence *)
- Node *CreateList(double *)
- Node *CreateNode(int, char, double, Node *, Node *, Node *, Node *)
- Node *InsertNode(Node *, Node *)
- void DestroyTree(Node *)
- void TraverseTree(Node *, char *, void (*ManipulateNode)(Node *, char *, void *), void *)
- void TraverseTreePreorder(Node *, char *, void (*ManipulateNode)(Node *, char *, void *), void *)
- void TraverseTreeforSave(Node *, char *, void (*ManipulateNode)(Node *, char *, void *), void *, FILE *)
- void TraverseTreeforRead(Node *, char *, void (*ManipulateNode)(Node *, char *, void *), void (*ManipulateNode1)(Node *pt_ActualNode, char *pt_Depth, void *pt_ExtraData, FILE *pt_file), void *, FILE *)
- void ReadLeftChildFromFile(Node *, char *, void *, FILE *)
- void ReadRightChildFromFile(Node *, char *, void *, FILE *)
- void DeleteNode(Node *, char *, void *)
- void AddNodeToCodingTable(Node *, char *, void *)
- SaveNodetoFile(Node *, char *, void *, FILE *)
- int CreateBitSequence(char *, BitSequence *)
- double PowerOf(long, int)
- int IsBitSet(int, char)
- void ShiftLeft(BitSequence *)
- int IsBitSetOfBS(BitSequence, unsigned char)
- BitSequence *CreateCodingTable(Node *)
- void DestroyCodingTable(BitSequence *)
- void CompressFile(FILE *, FILE *, BitSequence *, BitSequence, char)
- void DecompressFile(char *, char *)
- int WriteBitSequenceToFile(FILE *, BitSequence *, BitSequence *)
- char GetBitFromFile(FILE *, BitSequence *)
- char GetByteFromFile(FILE *, BitSequence *)
- int GetBitSequenceFromFile(FILE *, BitSequence *)
- BitSequence SaveTree(FILE *, Node *, BitSequence)
- void OpenFiletoSave(char *, char *, Node *, BitSequence *, char)
Top
Walter Scherer
nice.h
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
#include "memory.h"
#include "sys/stat.h"
#include "math.h"
- Diese Datei dient als zentrale Bibliothekseinbindungsdatei und wird in fast jede Source-Datei inkludiert
- Zur Erklärung der C-Headerdateien in einer ausführlichen Dokumentation nachsehen.
Top
Walter Scherer
parameter.h
int check_target_extension(char *filename);
int check_parameters_main(int argc, char *argv[]);
void usage();
Top
Walter Scherer
|